PDF-Explained
第3章 - 文件结构
在本章中,我们将描述PDF文件的四个主要部分的布局和内容, 以及构成每个部分的对象的语法。我们还概述了将PDF文件读入 高级数据结构的过程,以及将该结构写入PDF文件的相反操作。
File 布局
一个简单有效的PDF文件按顺序包含四个部分:
- header,提供PDF版本号
- body 包含页面,图形内容和大部分辅助信息的主体,全部编码为一系列对象。
- 交叉引用表,列出文件中每个对象的位置便于随机访问。
- trailer包括trailer字典,它有助于找到文件的每个部分, 并列出可以在不处理整个文件的情况下读取的各种元数据。
作为参考,我们从第2章再现”Hello,World”PDF作为例3-1。 四个部分中的每一部分的第一行都有注释。
Example 3-1. A small PDF file
%PDF-1.0 % Header从这里开始
%âãÏÓ
1 0 obj % Body从这里开始
<<
/Kids [2 0 R]
/Count 1
/Type /Pages
>>
endobj
2 0 obj
<<
25
/Rotate 0
/Parent 1 0 R
/Resources 3 0 R
/MediaBox [0 0 612 792]
/Contents [4 0 R]
/Type /Page
>>
endobj
3 0 obj
<<
/Font
<<
/F0
<<
/BaseFont /Times-Italic
/Subtype /Type1
/Type /Font
>>
>>
>>
endobj
4 0 obj
<<
/Length 65
>>
stream
1. 0. 0. 1. 50. 700. cm
BT
/F0 36. Tf
(Hello, World!) Tj
ET
endstream
endobj
5 0 obj
<<
/Pages 1 0 R
/Type /Catalog
>>
endobj
xref % 交叉引用表从这里开始
0 6
0000000000 65535 f
0000000015 00000 n
0000000074 00000 n
0000000192 00000 n
0000000291 00000 n
0000000409 00000 n
trailer % 预览块从这里开始
<<
/Root 5 0 R
/Size 6
>>
startxref
459
%%EOF
PDF文件中的对象集合形成图形。这个词图的意思 与饼图或直方图无关,而是指通过链接连接在一起的节点集合。
在我们的例子中,节点是PDF对象,链接是间接引用。读一个 PDF文档是在文件中创建PDF对象的图形的过程。这个 图是直接链接只走一条路。
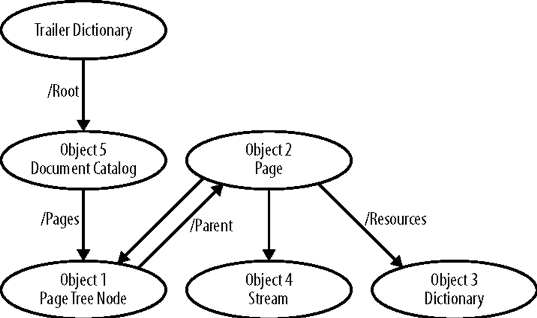
我们现在依次仔细研究这四个部分中的每一个,使用例3-1作为参考。
文件头
PDF文件的第一行给出文档的版本号。在我们的示例中,是:
%PDF-1.0
这将文件定义为PDF版本1.0。PDF是向后兼容的,因此PDF 1.3文档 应该由知道例如PDF 1.5的程序读取。它在很大程度上也是向前兼容的, 因此大多数PDF程序都会尝试读取任何文件,无论假设的版本号是什么。
由于PDF文件几乎总是包含二进制数据,因此如果更改行结尾 (例如,如果文件通过FTP以文本模式传输),它们可能会损坏。 为了允许传统文件传输程序确定文件是二进制文件, 通常在标头中包含一些字符代码高于127的字节。例如:
%âãÏÓ
百分号标识一行注释,其他几个字节是超过127的任意字符代码。 因此,我们示例中的整个header是:
%PDF-1.0
%âãÏÓ
Body
文件正文由一系列对象组成,每个对象前会有单独的一行,该行包括一个对象编号,一个世代号以及关键字obj。 紧跟在对象之后的是endobj关键字,它同样独占一行。例如:
1 0 obj
<<
/Kids [2 0 R]
/Count 1
/Type /Pages
>>
endobj
这里,对象编号是1,并且世代号是0(它几乎总是)。
对象1的内容位于1 0 obj和endobj两行之间。
在这种情况下,它是字典<</Kids [2 0 R] /Count 1 /Type /Pages >>
交叉引用表
交叉引用表列出了文件正文中每个对象的字节偏移量。 这允许随机访问对象,因此不必按顺序读取它们和对象 永远不会阅读从未使用过的。这尤其意味着,即使在大型文件上, 像计算PDF文档中的页数这样的简单操作也可以很快。
PDF文件中的每个对象都有一个对象编号和一个世代编号。 当重用交叉引用表条目时使用世代号 - 我们在这里不考虑它们(它们将始终为零)。
出于我们的目的,我们可以认为交叉引用表由一个表示条目数的标题行组成, 然后是一个特殊条目,然后是文件体中每个对象的一行。在我们的文件中:
0 6 % 表中的六个条目,从0开始
0000000000 65535 f % 特别条目
0000000015 00000 n % 对象1的字节偏移量为15
0000000074 00000 n % 对象2的字节偏移量为74
0000000192 00000 n % 等等...
0000000291 00000 n
0000000409 00000 n % 对象5的字节偏移量为409
请注意,字节偏移量以前导零存储,以确保每个条目都相同 长度。因此,我们也可以通过随机访问来读取交叉引用表。
文件尾
Trailer的第一行只是Trailer关键字。之后是Trailer 字典,至少包含/Size 条目(给出条目数在交叉引用表中)和 /Root条目(它给出了对象编号)文档目录,它是正文中对象图的根元素。
接下来是一行只包含startxref关键字, 一行包含一个数字(文件中交叉引用表开头的字节偏移量), 然后是行\%\%EOF,它表示PDF文件的结尾。
这是示例3-1中的Trailer:
trailer % 预览块关键字
<< % 预览块字典
/Root 5 0 R
/Size 6
>>
startxref % 交叉引用表开始关键字
459 % 交叉引用表的字节偏移量
%%EOF % 文件结束标记
从文件末尾向后读取Trailer:找到文件结束标记, 提取交叉引用表的字节偏移量,然后解析Trailer字典。 Trailer关键字标记Trailer的上限。
词汇约定
PDF文件是8位字节的序列。使用我们在本章中描述的规则, 这些字符可以分组为标记(例如关键字和数字)和文件解析。
一些通用规则适用于文件的主体,并且经常适用于PDF文件中的各种其他语言。 有三种字符:常规字符,空白字符和分隔符。表3-1中列出了空白字符。 分隔符是() <> [] {} / %,用于定义数组,字典等。 所有其他字符都是常规字符,没有特殊含义。
| 字符代码 | 含义 |
|---|---|
| 0 | Null |
| 9 | Tab |
| 10 | Line feed |
| 12 | Form feed |
| 13 | Carriage return |
| 32 | Space |
PDF文件可以使用<CR>,<LF>或<CR><LF>序列来结束一行。 但请注意,一起更改行结尾(例如,在文本编辑器中)可能会破坏文件, 因为它将改变在压缩二进制数据部分中发生的任何行结束序列。
对象
PDF支持五个基本对象:
- 整数和实数,例如42和3.1415
- 字符串,括在括号中,并有各种编码。例如
(The Quick Brown Fox)。 - 名称,用于词典中的键,以及无数其他用途。它们带有/,例如/Blue。
- 布尔值,由关键字true和false表示。
- null对象,由关键字null表示。
和三个复合对象:
- 数组,包含其他对象的有序集合,如
[1 0 0 0]。 - 字典,由无序的对集合组成,将名称映射到对象。
例如,
<</Contents 4 0 R /Resources 5 0 R >>, 其将/Contents映射到间接引用4 0 R和/Resources到间接引用5 0 R. - 包含二进制数据的流以及描述数据属性的字典, 例如其长度和任何压缩参数。流用于存储图像,字体等。 以及将对象链接在一起的方法:
- 间接引用,它形成从一个对象到另一个对象的链接
PDF文件由对象图组成,间接引用形成它们之间的链接。例3-1的对象图如图3-1所示。
整数和实数
整数写为一个或多个十进制数字0..9,可选地以加号或减号开头:
0 +1 -1 63
实数被写为一个或多个十进制数字,可选地前面带有加号或减号, 并且可选地有一个小数点,可以是内部, 或以下:
0.0 0. .0 -0.004 65.4
通常,规范允许给定对象是整数或实数。其他时候它必须是整数。 此外,整数和实数的范围和准确性由PDF实现定义,而不是标准。 在某些实现中,如果整数超出可用范围,则将其转换为实数。
字符串
字符串由一系列字节组成,写在括号之间:
(Hello, World!)
反斜杠\字符和括号字符()必须通过在它们前面加上反斜杠进行转义。例如,写作:
(Some \\ escaped \(characters)
表示字符串”Some \ escaped (characters)”。外部存在已经平衡的括号对
在字符串内不需要转义。例如(Red(Rouge))表示字符串“Red(Rouge)”。
反斜杠也可用于引入其他字符代码以实现可读性(参见表3-2)。
| 字符序列 | 含义 |
|---|---|
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \b | 退格 |
| \f | 换页符 |
| \ddd | 三个八进制数字的字符代码 |
从文件中读取字符串后,转义的转义字符将产生形成字符串的字节序列,然后可以按照第45页的“文本字符串”中的描述进行解释。
十六进制字符串
字符串也可以写为<和>之间的十六进制数字序列,每对代表一个字节:
<4F6Eff00> Bytes 0x4F, 0x6E, 0xFF, and 0x00
当存在奇数个数字时,假设最后一个为十六进制字符串通常用于使二进制数据用户可读。 它在功能上与以通常方式描述字符串相同。
名称
名称在整个PDF中使用,作为字典的键和定义各种多值对象, 其中使用整数枚举它们将是不直观的。一个名称 引入正斜杠。例如:
/French
/字符是名称的一部分 - 事实上,/它本身就是一个有效的名称。 名称可能不包含空格或分隔符,但名称需要与之对应 一些具有这些字符的外部名称(例如空格),我们可以使用哈希符号后跟两个十进制数字:
/Websafe#20Dark#20Green
这表示名称/Websafe Dark Green,因为在ASCII中, 十六进制20是空格的代码。名称区分大小写(/French和/french不同)。
布尔值
PDF允许布尔值为true和false。它们经常在字典条目中用作标志。
数组
数组表示PDF对象的有序集合,包括其他数组。对象不一定都是同一类型。例如,数组:
[0 0 400 500]
按顺序包含四个数字:0,0,400,500。数组:
[/Green /Blue [/Red /Yellow]]
包含三个项目:名称/Green,名称/Blue和两个名称的数组[/Red /Yellow].
字典
字典表示键值对的无序集合。字典将键映射到值 - 提供键, 值是在字典中查找的结果。键是名称,值可以是任何PDF对象。 字典写在<<和>>之间。例如:
<</One 1 /Two 2 /Three 3>>
将名称/One映射到整数1,将名称/Two映射到整数2, 将名称/Three映射到整数3.字典当然可以包含其他字典。 嵌套字典构成了大多数PDF文件中的大部分非图形结构化数据。
间接引用
为了将PDF内容拆分为单独的对象(因此只有在需要时才能读取数据), 我们将它们与间接引用连接在一起。对对象6的间接引用写为:
6 0 R
这里,6是对象编号,0是世代号(这里我们不考虑),R是间接参考关键字。
例如,这是使用间接引用的典型字典:
<< /Resources 10 0 R
/Contents [4 0 R] >>
在此示例中,对象10和4在字典的值中被引用。
流和过滤器
流用于存储二进制数据。它们由字典和一大块二进制数据组成。 字典根据流所放置的特定用途列出数据的长度,以及可选的其他参数。
从语法上讲,流由字典组成,后跟stream关键字, 换行符(<LF>或<CR> <LF>),零个或多个字节的数据, 另一个换行符,最后是endstream关键字。从我们的示例文件中:
4 0 obj % 对象4
<<
/Length 65 % 数据长度
>>
stream % 流关键字
1. 0. 0. 1. 50. 700. cm % 65字节的数据,这里是图形流
BT
/F0 36. Tf
(Hello, World!) Tj
ET
endstream % 结束流关键字
endobj % 对象的结束
这里,字典只包含/Length条目,它以字节为单位给出流的长度。
所有流必须是间接对象。流几乎总是使用各种机制进行压缩,如表3-3所示。
| 方法名称 | 描述 |
|---|---|
| /ASCIIHexDecode | 为压缩数据中的每对十六进制数字生成一个字节的未压缩数据。>表示数据结束。空格被忽略。这个过滤器和/ASCII85Decode旨在将数据减少到7位——/ASCII85Decode更复杂,但更紧凑 |
| /ASCII85Decode | 这种7位编码格式使用可打印的字符从 ! 到 u 和 Z。(译者注:即通过五个ASCII字符来表示四个字节的二进制数据。)~>标识数据结束 |
| /LZWDecode | 实现Lempel-Ziv-Welch压缩,如TIFF图像格式所使用 |
| /FlateDecode | Flate压缩,由开源zlib库使用。在RFC 1950中定义。/LZWDecode和/FlateDecode都可以在流字典中具有预测变量,它们定义数据的后处理以反转在压缩时完成的预处理 |
| /RunLengthDecode | 一个简单的基于字节的游程压缩器 |
| /CCITTFaxDecode | 实现传真机使用的第3组和第4组编码。适用于单色(位深度为1)图像,不适用于一般数据 |
| /JBIG2Decode | 一种更现代,更好的压缩机制,适用于与/CCITTFaxDecode一起使用的各种数据,但也适用于灰度和彩色图像和一般数据。实现JBIG2压缩方法 |
| /DCTDecode | JPEG有损压缩。整个JPEG文件可以放在这里,包括JPEG文件头 |
| /JPXDecode | JPEG2000有损和无损压缩。仅限于JPX基准功能集,但有一些例外 |
以下是压缩流的示例:
796 0 obj
<</Length 275 /Filter /FlateDecode>> % 流
HTKO0÷ü % 这里还有 268 字节被隐藏,即总计 275 字节
endstream
endobj
通过为流的字典中的/Filter条目指定数组而不是名称,可以使用多个过滤器。
例如,使用JPEG方法压缩然后使用ASCII85编码的图像可能具有以下过滤条目:
/Filter [/ASCII85Decode /DCTDecode]
需要外部参数的过滤器(例如,在数据流本身之外定义压缩参数)也会将这些参数存储在流字典中。
Incremental Update 增量更新
增量更新允许通过将修改附加到文件末尾来更新文件, 因此不需要再次写入整个文件(对于大文件,可能需要很长时间)。 更新构成新的或更改的对象,以及对交叉引用表的更新。 这意味着保存更改所花费的时间更少,但文件可能会变得臃肿(因为不再需要的对象无法删除)。
此更新过程可能会发生多次。副作用是以这种方式更新的 文件可能会使这些更改撤消一个或多个级别,以检索文档的早期版本。
更改经过数字签名的文档时,必须以增量方式进行所有更新 - 否则, 数字签名将无效。收件人可以撤消增量更新以检索原始的,经过认证的文档。
当一个文件以递增方式更新时,会添加一个新的trailer,其中包含前一个trailer 中的所有条目,以及一个/Prev条目,它给出了之前交叉引用表的字节偏移量。 因此,已逐步更新的文件将具有多个trailer词典和文件结束标记。 通过这种方式,PDF应用程序可以以相反的顺序读取交叉引用部分, 以构建文件中每个对象的最新版本的列表。已替换的对象保持相同的对象编号。
Object and Cross-Reference String 对象和交叉引用流
从PDF 1.5开始,引入了一种新机制,通过允许将多个对象放入单个 对象流中来进一步压缩PDF文件,整个流被压缩。 同时,引入了一种用于引用这些流中的对象的新机制 - 交叉引用流。
文件通常使用几组对象流,将特定时间所需的对象组合在一起, 例如第一页上的所有对象,第二页上的所有对象,等等。 这保留了文档的随机访问属性,如果将文件中的所有对象放入 单个对象流中,该属性将丢失。对象流不能包含其他流。
使用这些机制压缩的文件很难手动读取,因此我们可以像往常 一样使用pdftk中的解压缩操作,将它们重写为解压缩以供检查。 这具有在没有对象和交叉引用流的情况下编写它们的副作用。详细信息请参见第9章。
Linearized PDF 线性化 PDF
在网络环境中查看大型PDF文件时,尤其是当数据速率较低或网络延迟较高时, 用户不希望等待整个文件下载以查看它。在Web浏览器中查看文档时,这一点尤为重要。
我们希望第一页快速显示,并且要更改为另一页(通过单击超链接或书签)尽可能快。 在个人的情况下页面大(而不仅仅是整个文档),我们应该首先看页面内容是增量, 最重要的内容。网络传输机制例如HTTP(超文本传输协议,用于在Web浏览器中获取网页) 通常允许获取任意数据块。但是,因为延迟,我们希望获取一个包含页面所有数据的块, 而不是数百个小块,每个对象一个。
PDF 1.2引入了这样一种机制,线性化PDF。 这将添加有关如何对文件中的对象进行排序以及提示表以指示如何对这些对象进行排序的规则。 该系统是向后兼容的,因此线性化的PDF文件也是正常的, 并且可以由不理解线性化PDF的阅读器读取。
线性化的PDF文件可以通过文件顶部直接在标题之后存在线性化字典来识别。例如:
%PDF-1.4
%âãÏÓ
4 0 obj
<< /E 200967
/H [ 667 140 ]
/L 201431
/Linearized 1
/N 1
/O 7
/T 201230
>>
endobj
GhostScript附带的pdfopt命令行程序可以线性化文件。例如:
pdfopt input.pdf output.pdf
这会使input.pdf线性化并将结果写入output.pdf。
如何读取PDF文件
要读取PDF文件,将其从一系列平坦的字节转换为内存中对象的图形, 通常可能会发生以下步骤:
- 从文件开头读取PDF header,确认这确实是PDF文档并检索其版本号。
- 现在通过从末尾向后搜索找到文件结束标记 文件。现在可以读取trailer字典,以及开头的字节偏移量检索交叉引用表。
- 现在可以读取交叉引用表。我们现在知道每个对象在文件的什么地方了。
- 在此阶段,可以读取和解析所有对象,或者我们可以离开此过程 直到实际需要每个对象,按需阅读。
- 我们现在可以使用数据,提取页面,解析图形内容,提取元数据等。 这不是详尽的描述,因为存在许多可能的复杂性(加密,线性化,对象和交叉引用流)。 以下伪代码中给出的递归数据结构可以包含PDF对象。
pdfobject ::= Null
| Boolean of bool
| Integer of int
| Real of real
| String of string
| Name of string
| Array of pdfobject array
| Dictionary of (string, pdfobject) array Array of (string, pdfobject) pairs | Stream of (pdfobject, bytes) Stream dictionary and stream data
| Indirect of int
例如,对象« /Kids [2 0 R] /Count 1 /Type /Pages »可能表示为:
Dictionary
((Name (/Kids), Array (Indirect 2)),
(Name (/Count), Integer (1)),
(Name (/Type), Name (/Pages)))
本章前面的图3-1显示了例3-1中文件的对象图。
如何编写PDF文件
将PDF文档写入文件中的一系列字节要比阅读它简单得多, 我们不需要支持所有PDF格式,只需要支持我们打算使用的子集。写作 PDF文件非常快,因为它只是将对象图展平为一系列字节。
- 输出header。
- 删除PDF中任何其他对象未引用的任何对象。这个避免编写不再需要的对象。
- 重新编号对象,使它们从1到n运行,其中n是对象的数量文件。
- 逐个输出对象,从对象编号1开始,记录字节交叉引用表的每个偏移量。
- 编写交叉引用表。
- 编写trailer,trailer字典和文件结束标记
| 目录 | 上一章:构建一个简单的PDF | 下一章:文档结构 |