PDF-Explained
第2章 - 构建一个简单的PDF
在本章中,我们将在文本编辑器中手动构建PDF内容。然后我们将使用 免费的pdftk程序将其转换为有效的PDF文件,并在PDF查看器中查看输出。
此示例以及本书中的所有PDF文件都可以从中这本书的网页下载。
我们将同时考虑很多新概念,所以不要担心, 如果看起来压倒一切 - 我们将在以后的章节中回到这一切。
补充pdftk介绍信息
基本PDF语法
PDF文件至少包含三种不同的语言:
- document content文档内容,是在它们之间具有链接的多个对象,形成有向图。这些对象描述了文档的结构(页面,元数据,字体和资源)。
- page content页面内容,描述了使用一系列操作符将文本和图形放在一个页面上。
- file structure文件结构,包括header(文件头),trailer(文件尾)和交叉引用表,帮助程序找到并读取文件的内容。
Document Content
文档内容包括由以下元素构建的对象:
- 名称,写为
/Name - 整数,如
50 - 带圆括号的字符串,如
(The Quick Brown Fox) - 引用其他对象,如
2 0 R,对对象2的引用。 - 对象的数组(有序集合),如
[50 30 /Fred],是一个包含三个项目的数组,按顺序:50,30和/Fred。 - 字典(从名称到对象的无序映射),如
<</Three 3 /Five 5>>,映射/Three到3和/Five到5。 - stream(流),它由字典和一些二进制数据组成。这些用于存储PDF图形运算符的流,以及其他二进制数据,如图像和字体。
例如,这是一个页面对象,它是一个包含许多项目的字典,每个与名称相关联:
<< /Type /Page
/MediaBox [0 0 612 792]
/Resources 3 0 R
/Parent 1 0 R
/Contents [4 0 R]
>>
这个词典包含五个条目:
/Type /Page
名称 /Page 与字典键 /Type 相关联。
/MediaBox [0 0 612 792]
四个整数 [0 0 612 792] 的数组与字典键 /MediaBox 相关联。
/Resources 3 0 R
对象编号3与字典键 /Resources 相关联。
/Parent 1 0 R
对象编号1与字典键 /Parent 对象相关联。
/Contents [4 0 R]
间接引用 [4 0 R] 的单元素数组与字典键 /Contents 相关联。
Page Content
页面内容是运算符列表,每个运算符前面都有零个或多个 操作数。这是一系列操作符,用于在36号字体选择/F0字体并放置 当前位置的文字:
/F0 36.0 Tf
(Hello, World!) Tj
这里,Tf 和 Tj 是运算符,而 /F0, 36.0 和 (Hello, World!) 是操作数。
你可以看到一些语法元素(例如,名称和字符串)是共享的跨页面内
容和文档内容使用的语言。
文件结构
文件结构包括:
- 用于将文件区分为PDF文档的header(文件头)。
- 一个交叉引用表,列出了文档中每个对象的字节偏移量 - 这个 允许任意访问对象,而不是必须按顺序读取。
- trailer(文件尾),包括交叉引用表的字节偏移,后跟文件结束标记。
在编写我们的示例文件时,我们将对许多文件结构使用不完整的值, 依靠pdftk来填写细节。例如,我们手动编写交叉引用表是不切实际的。
Document 结构
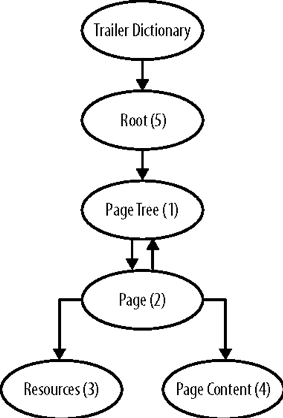
我们将要构建的示例只是最简单有意义的PDF文件。然而, 它需要大量的元素。除了我们的文件结构 如上所述,最小的PDF文档必须包含许多基本部分:
- trailer字典,提供有关如何阅读其余内容的信息文件中的对象
- 文档目录,它是对象图的根。
- 页面树,它枚举文档中的页面。
- 至少有一页。每个页面必须具有:
-
- resources(资源),包括例如字体。
-
- 其页面内容,其中包含绘制文本和图形的说明在页面上。
-
这种安排如图2-1所示。
构建元素
我们将PDF数据输入到文本文件中。 文本编辑器选择的行结尾并不重要(<LF>[在 Unix 和 Mac OS X 中]和 <CR><LF>[在 Windows 中]都很好)。 我们将跳过一些信息(手动难以解决的数据),依靠pdftk来填充它。我们会:
- 使用简短的header。
- 跳过了页面内容流的长度,因此我们不必手动计数字节数。
- 省略几乎所有的交叉引用表
- 使用0表示交叉引用表的字节偏移量,以避免必须计数它手动。
首先,我们将查看文件的各个部分(按照它们出现的顺序)然后查看 我们将它们放在一起并运行pdftk来制作有效的PDF文件。
文件头
文件头通常由两行组成。第一行将文件标识为PDF和 给出它的版本号:
%PDF-1.0 % PDF 版本号为 1.0 的文件头
第二行很难输入文本编辑器,因为它包含不可打印的字符。 我们将有pdftk为我们这样做。
主要对象
到文件的主体-对象。第一个是Page列表,它是链接到文档中页面对象的字典。
1 0 obj % 对象1
<< /Type /Pages % 这是一个页面列表
/Count 1 % 只有一页
/Kids [2 0 R] % 页面对象编号列表。这里只是对象2
>>
endobj % 对象1结束
接下来是页面。再次,它是一个字典。它包含纸张大小,间接 引用返回页面列表,以及图形内容和资源。
2 0 obj
<< /Type /Page % 这是一个页面
/MediaBox [0 0 612 792] % 纸张尺寸为美国信肖像(612点x792点)
/Resources 3 0 R % 对象3的资源引用
/Parent 1 0 R % 引用备份到父页面列表
/Contents [4 0 R] % 图形内容在对象4中
>>
endobj
现在,资源(resource)。在这里,只有一个条目,字体字典,在我们的 示例包含单个字体,我们将使用该字体在页面上写入一些文本。
3 0 obj
<< /Font % 字体字典
<< /F0 % 只有一种字体,称为/F0
<< /Type /Font % 这三行引用了内置字体Times Italic
/BaseFont /Times-Italic
/Subtype /Type1 >>
>>
>>
endobj
图形内容
页面内容流包含用于放置文本和图形的一系列运算符
在页面上。它通过页面字典中的 /Contents 条目链接。
流对象由字典后跟原始数据流组成,包含一个
一系列PDF操作数和运算符。通常,这将被压缩以减少
文件大小,但我们手动输入,所以我们不压缩它。
我们还必须以字节为单位指定流的长度-pdftk将为我们添加所需的
/Length 条目到流字典。
4 0 obj % 页面内容流
<< >>
stream % 流的开始
1. 0. 0. 1. 50. 700. cm % 位置在(50,700)
BT % 开始文本块
/F0 36. Tf % 在36pt选择/F0字体
(Hello, World!) Tj % 放置文本字符串
ET % 结束文本块
endstream % 流结束
endobj
页面上的图形运算符流的结果如图2-2所示。

目录,交叉引用表和文件尾
文件的最后一部分以文档目录开头,该目录是文档目录的根对象
对象图。接下来是交叉引用表,它给出了字节偏移量
文件中的每个对象。我们将pdftk为我们填写此内容。最后两行:一行
给出交叉引用表开始的字节偏移量(我们写0和pdftk将
替换它为我们)。最后,文件结束标记 %%EOF。
5 0 obj
<< /Type /Catalog % 文件目录
/Pages 1 0 R % 参考页面列表
>>
endobj
xref % 我们跳过了交叉引用表的开始
0 6
trailer
<< /Size 6 % 交叉引用表中的行数(对象数加1)
/Root 5 0 R % 参考文档目录
>>
startxref
0 % xref表开始的字节偏移量,我们将其设置为0
%%EOF % 文件结束标记
现在我们准备将这些部分放在一起了
把它放在一起
可以在此在线资源中找到书此文件的源(示例2-1), 或者你可以自己输入。将其保存为hello-broken.pdf。
例2-1。无效的hello-broken.pdf PDF文件适合手动创建
%PDF-1.0 % 文件header
1 0 obj % 主要对象
<< /Type /Pages
/Count 1
/Kids [2 0 R]
>>
endobj
2 0 obj
<< /Type /Page
/MediaBox [0 0 612 792]
/Resources 3 0 R
/Parent 1 0 R
/Contents [4 0 R]
>>
endobj
3 0 obj
<< /Font
<< /F0
<< /Type /Font
/BaseFont /Times-Italic
/Subtype /Type1 >>
>>
>>
endobj
4 0 obj % 图形内容
<< >>
stream
1. 0. 0. 1. 50. 700. cm
BT
/F0 36. Tf
(Hello, World!) Tj
ET
endstream
endobj
5 0 obj % 目录,交叉引用表和trailer
<< /Type /Catalog
/Pages 1 0 R
>>
endobj
xref
0 6
trailer
<< /Size 6
/Root 5 0 R
>>
startxref
0
%%EOF
就目前而言,hello-broken.pdf不是有效的PDF文件,甚至也不是Adobe Reader(其中 相当容忍格式错误的文件)将无法应对。
译注: Adobe Acrobat 2018 已经可以直接打开
hello-broken.pdf文件。 打开后关闭时,会提示是否需要保存。查看保存的 PDF 发现使用 PDF 1.6 规范并且已经线性化。开源的 SumatraPDF v3.2 也可以直接打开。
我们可以使用免费的pdftk工具来修复hello-broken.pdf文件,其中包含缺少的细节, 将输出写入hello.pdf:
pdftk hello-broken.pdf output hello.pdf
pdftk读取文件及其对象,并为缺失或计算正确的数据 我们写的错误部分,并生成示例2-2中显示的有效文件。注意 一些语法的间距和格式已经改变 - 每个PDF制做人对此有不同的选择。
例2-2。完成的PDF文件hello.pdf,由pdftk修复
%PDF-1.0
%âãÏÓ % ❶
1 0 obj
<<
/Kids [2 0 R]
/Count 1
/Type /Pages
>>
endobj
2 0 obj
<<
/Rotate 0
/Parent 1 0 R
/Resources 3 0 R
/MediaBox [0 0 612 792]
/Contents [4 0 R]
/Type /Page
>>
endobj
3 0 obj
<<
/Font
<<
/F0
<<
/BaseFont /Times-Italic
/Subtype /Type1
/Type /Font
>>
>>
>>
endobj
4 0 obj
<<
/Length 65 % ❷
>>
stream
1. 0. 0. 1. 50. 700. cm
BT
/F0 36. Tf
(Hello, World!) Tj
ET
endstream
endobj
5 0 obj
<<
/Pages 1 0 R
/Type /Catalog
>>
endobj xref
0 6 % ❸
0000000000 65535 f
0000000015 00000 n
0000000074 00000 n
0000000192 00000 n
0000000291 00000 n
0000000409 00000 n
trailer
<<
/Root 5 0 R
/Size 6
>>
startxref
459 % ❹
%%EOF
1: 一些不可打印的字符已添加到PDF标题中 - 这可确保文件被识别为二进制 (而不是文本),例如,通过FTP等文件传输程序。
2: 已填写流的字节长度。
3: 交叉引用表已填入了每个对象的字节偏移量文件。
4: 已填写交叉引用表开头的字节偏移量。
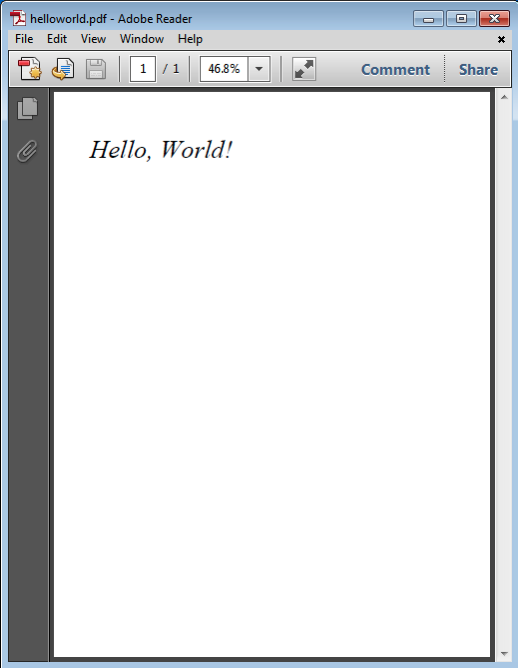
该文件现在可以加载到PDF查看器中。Microsoft Windows上的Acrobat Reader的结果如图2-3所示。
备注
我们已经看到了如何从头开始构建一个简单的PDF文件,使用pdftk来帮助我们,以及 我们已经看了一些构成PDF文档的基本语法。
你也可以使用文本编辑器查看现有的PDF文件。但是,有些 数据(例如构成页面内容的图形运算符)很可能被压缩,因此不可读。 pdftk命令可用于解压缩这些 部分以便于阅读 - 请参阅第114页的“压缩”。
在以后的章节中,我们将详细介绍典型PDF文件的各个部分以及如何进行 程序读取,写入和编辑PDF文件。在每个阶段,都有机会 通过改变和扩展我们在本章中构建的示例来构建示例文件。
| 目录 | 上一章:介绍 | 下一章:文件结构 |